

Copyright and the NYTimes-OpenAI Lawsuit
I find the implications of the NYTimes lawsuit against OpenAI so disheartening for education. It’s not that OpenAI is the angelic victim while the NYTimes is the evil predator—OpenAI is far from innocent in their dealings. Rather, this appears to be a money-grab maneuver with complete disregard to the broad impact for copyright and fair use. There have been other lawsuits as well, including book authors and OpenAI, so this needs to be resolved sooner than later.
Many content creators believe that training an AI with their content is wrong, even if it was paid for legitimately (while that last point is somewhat in question, for the sake of this writing let’s assume it was legitimately purchased). The specifics of training an AI are not the same as a human, but it is very parallel in process to humans expanding our knowledge and skills with new content. To me, the main issue is not the gathering and training—it is how the content is used as a service.
The demands in the lawsuit involve compensation by the AI organizations. The frustrating part is that academia has struggled for decades on this issue, and yet no one seems to acknowledge those solutions already exist and can be applied here.
“In the end, though, the crux of this lawsuit is the same as all the others. It’s a false belief that reading something (whether by human or machine) somehow implicates copyright. This is false. If the courts (or the legislature) decide otherwise, it would upset pretty much all of the history of copyright and create some significant real world problems (Masnick, 2023).”
Copyright does not protect ideas, it protects the expression of those ideas. If someone uses ideas gained from reading/viewing someone else’s work, that is a legitimate use and not an infringement of copyright. At the core, if someone consumes content (articles, books, videos) on a topic and then creates a service that utilizes the knowledge gained from that content (and potentially makes money doing it), it that wrong? No. Isn’t this what the entire educational process is about? Then take it a step further: if a machine consumes content (articles, books, videos) on a topic and then creates a service that utilizes the knowledge gained from that content (and potentially makes money doing it), it that wrong?
In academia, typically individuals expand their knowledge/skills and then in some form demonstrate their gain in knowledge/skills. The line is crossed when people portray someone else’s work as their own (plagiarism). The solution has been refined over the years, and is primarily resolved by citation and fair use guidelines. We have process for citing direct quotation, and we also have process for citations of paraphrased content.
If the NYTimes and authors were truly worried about AI regurgitating their content and taking away their business, the simplest solution is to build citation into the tools, both for direct quotes and paraphrased content, and then determine limits for both (fair use).
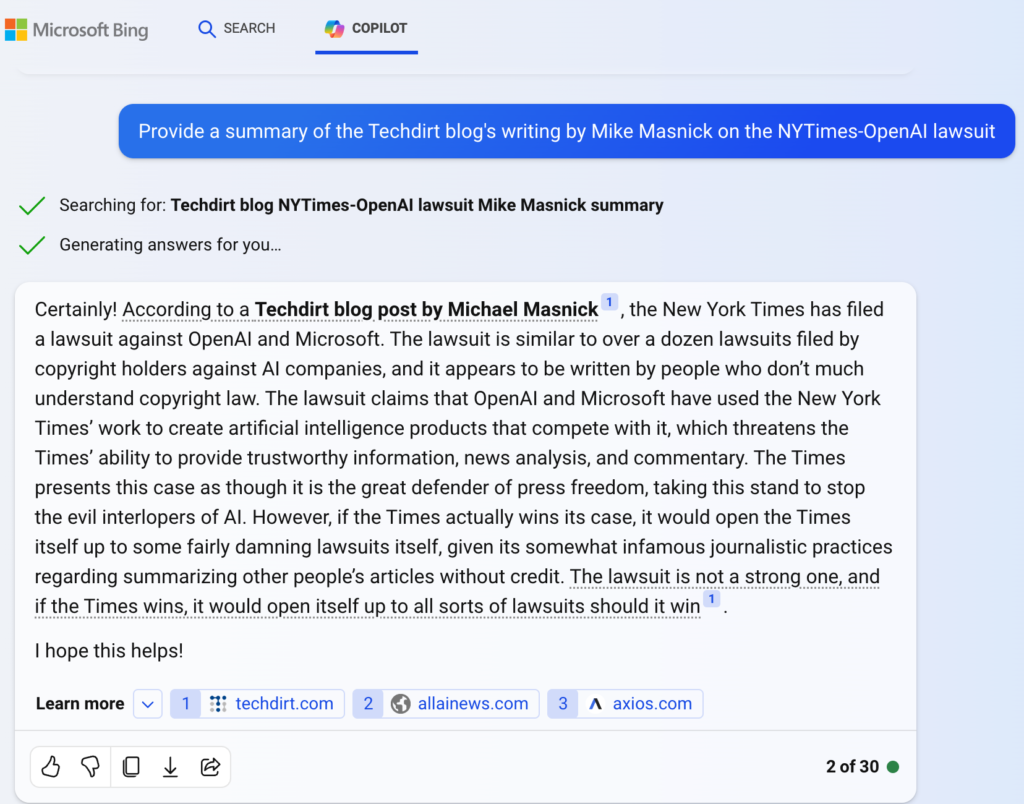
But clearly that is not what they are after—even now, some AIs, including Microsoft/OpenAI Copilot, already utilize citations (See Figure1 below). Rather, this appears to be a concerted effort to expect monetary exchange for consumption and use of content, even if access to the content has already been paid for.
For education, this is disastrous on two fronts. First, this lawsuit has huge ramifications on the entire copyright/fair use process, which educators depend on every day (one could argue this whole problem here is caused by such weak, incomplete laws on fair use but that is for another discussion). Ultimately this infringes on everyone’s right to read. We can’t absorb fees for access and then barriers or limitations for consumption/use. Ideas cannot be copyrighted currently, but this lawsuit brings us closer to ownership of ideas no matter how they are expressed and limits others from expanding on those ideas. Second, if there is another fee for use of the content beyond access, the growing tools of AI will be limited to huge tech companies with deep pockets and push out all the smaller, specialty players. That would be a disaster for all the niche tools geared for education and completely dampen innovation in the field.
I don’t want this to come across as “the-sky-is-falling” hysteria, but do pay attention to these lawsuits. They could alter the core of what copyright means, and potentially spell trouble for the entire educational process.
Resources
Masnick, M. (2023, December 28). The NY Times lawsuit against OpenAI would open up the NY Times to all sorts of lawsuits should it win. Techdirt. https://www.techdirt.com/2023/12/28/the-ny-times-lawsuit-against-openai-would-open-up-the-ny-times-to-all-sorts-of-lawsuits-should-it-win/
Microsoft. (2024, January 10). Microsoft Copilot. Bing Chat. computer software. Retrieved January 10, 2024, from https://www.bing.com/search?q=Bing+AI&showconv=1&FORM=undexpand.





